안녕하세요! 여러분, AI 기술의 발전에 늘 흥미를 느끼는 저도 최근에는 정말 깜짝 놀랄 만한 소식을 접했는데요. 바로 **Qwen3-Next**라는 새로운 AI 모델 아키텍처 이야기입니다 😊. 대형 언어 모델(LLM)을 다루다 보면 늘 '학습은 너무 오래 걸리고, 추론은 느리고…' 이런 고민을 하게 되죠. 저도 얼마 전까지는 이런 문제 때문에 밤을 새운 적이 한두 번이 아니었어요. 그런데 Qwen3-Next는 이런 비효율성을 극복하기 위해 아예 새로운 방식으로 설계되었다고 해요. 오늘은 이 혁신적인 모델이 대체 어떤 기술을 담고 있는지, 왜 기존 모델보다 월등한 성능을 보이는지 자세히 파헤쳐 보려고 합니다.
Qwen3-Next, 무엇이 다른가요? 💡
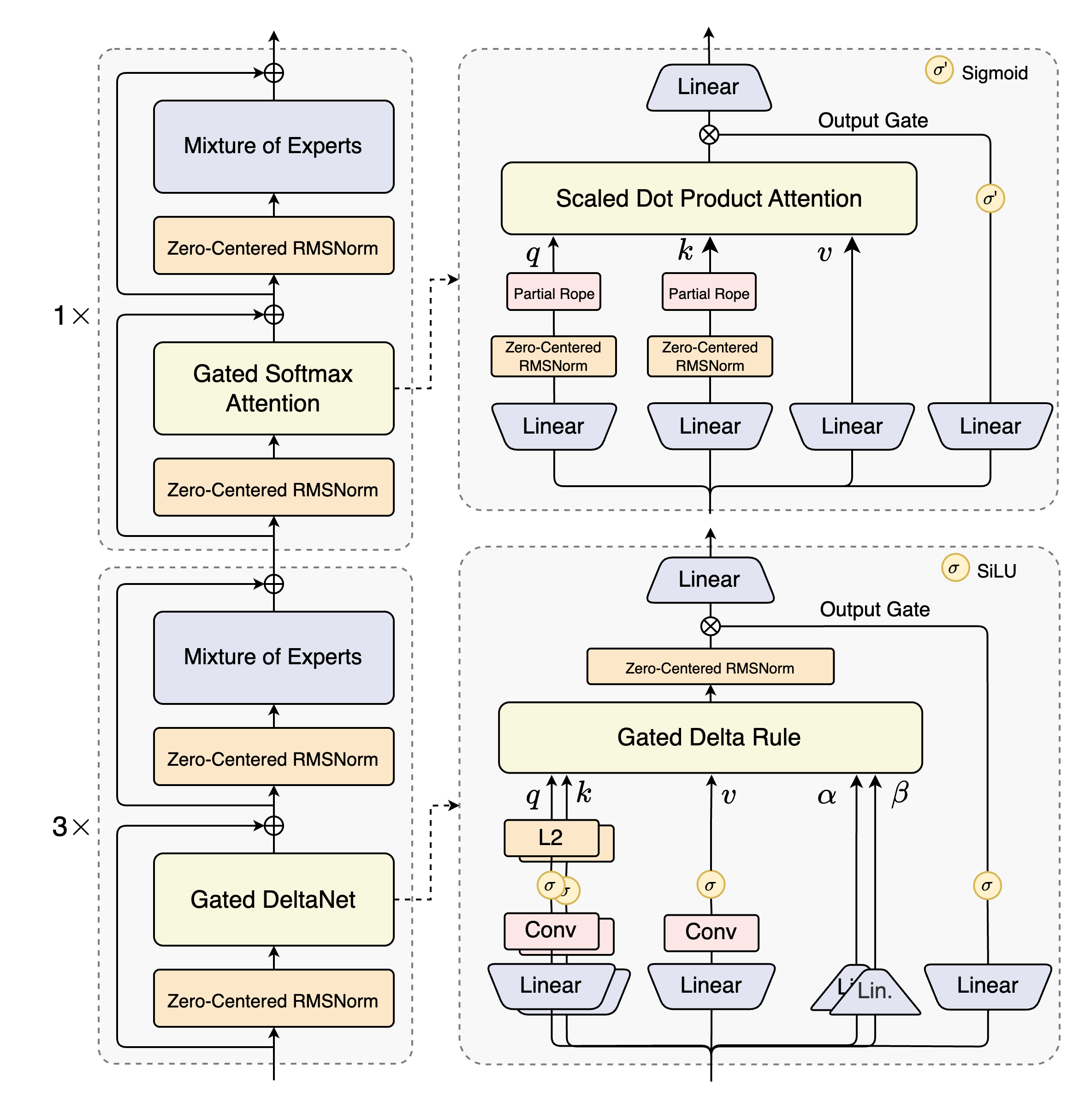
Qwen3-Next의 가장 큰 특징은 바로 **하이브리드 아키텍처**와 **초고밀도 희소 MoE** 구조예요. 기존 모델들은 스탠다드 어텐션(Standard Attention)이나 선형 어텐션(Linear Attention) 중 하나만 사용하곤 했는데요. 스탠다드 어텐션은 강력하지만 문맥 길이가 길어지면 계산량이 기하급수적으로 늘어나고, 선형 어텐션은 빠르지만 정보 기억력이 약하다는 단점이 있었죠.
Qwen3-Next는 이 둘의 장점만 쏙쏙 뽑아냈어요. **Gated DeltaNet**과 스탠다드 어텐션을 3:1 비율로 혼합해서, 성능과 효율성을 모두 잡았답니다. 이 하이브리드 접근법 덕분에 어떤 단일 아키텍처보다 뛰어난 성능을 일관되게 보여준다고 해요.
Gated DeltaNet은 기존의 슬라이딩 윈도우 어텐션(Sliding Window Attention)이나 Mamba2 같은 방식보다 문맥 내 학습 능력이 훨씬 뛰어나다는 사실. 긴 문맥을 다루는 데 특히 유리한 이유가 바로 여기에 있어요.
경이로운 효율성: 학습 비용과 추론 속도 🚀
Qwen3-Next의 가장 놀라운 점은 바로 **압도적인 효율성**이에요. 800억 개의 총 파라미터를 가지고 있지만, 실제 추론 단계에서는 불과 30억 개의 파라미터만 활성화됩니다. 기존의 Qwen3 MoE 모델(128개 전문가 중 8개 활성화)보다 훨씬 더 희소한 구조를 사용하죠.
이러한 구조 덕분에 Qwen3-Next는 Qwen3-32B 모델보다 적은 학습 비용(9.3%)을 사용하고도, 오히려 더 좋은 성능을 달성했어요. 특히 추론 단계에서는 그야말로 혁신적입니다.
추론 속도 비교 (Qwen3-Next-80B vs Qwen3-32B) 📊
| 단계 | 4K 문맥 길이 | 32K+ 문맥 길이 |
|---|---|---|
| **Prefill** (입력 처리) | 약 7배 더 빠름 | 10배 이상 더 빠름 |
| **Decode** (출력 생성) | 약 4배 더 빠름 | 10배 이상 더 빠름 |
Qwen3-Next는 하이브리드 어텐션 구조의 불안정성을 해소하기 위해 **Zero-Centered RMSNorm**과 **가중치 감소(weight decay)** 같은 안정화 기술을 도입했어요. 덕분에 소규모 실험은 물론, 대규모 학습도 문제없이 진행할 수 있다고 합니다.
탁월한 성능: Instruct와 Thinking 모델 📚
Qwen3-Next의 우수성은 벤치마크 점수로도 증명됩니다. 특히 초장문맥(Ultra-long context) 작업에서 그 진가를 발휘하는데요. Qwen3-Next-80B-A3B-Instruct 모델은 256K 토큰까지의 긴 문맥 작업에서 Qwen3-235B-A22B 모델과 비슷한 성능을 보여줘요. 이는 하이브리드 어텐션 설계가 얼마나 효과적인지를 증명하는 결과입니다.
추가적으로, 복잡한 추론 작업에 특화된 **Qwen3-Next-80B-A3B-Thinking** 모델도 놀라운 성능을 보여줍니다. 이 모델은 기존의 Qwen3-30B-A3B-Thinking-2507 모델이나 Gemini-2.5-Flash-Thinking 같은 모델을 뛰어넘는 결과를 보여주며, 심지어 최고 성능 모델인 Qwen3-235B-A22B-Thinking-2507의 성능에 근접했다고 해요.
실전 예시: Qwen3-Next 활용법 👩💻
Qwen3-Next 모델은 허깅 페이스(Hugging Face)와 모델스코프(ModelScope)에 이미 공개되었고, 알리바바 클라우드 모델 스튜디오와 엔비디아 API 카탈로그를 통해서도 사용할 수 있어요. 실제로 어떻게 활용하는지 간단하게 살펴볼까요?
Hugging Face에서 모델 사용하기 💻
**Hugging Face Transformers** 라이브러리를 통해 간단하게 모델을 사용할 수 있습니다. 아래 코드는 Qwen3-Next-80B-A3B-Instruct 모델을 로드하여 텍스트를 생성하는 예시예요.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# 토크나이저와 모델 로드
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# 모델 입력 준비
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 텍스트 생성
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
이 코드를 실행하려면 `transformers` 라이브러리의 메인 브랜치를 설치해야 합니다. `pip install git+https://github.com/huggingface/transformers.git@main` 명령어를 사용해 보세요.
SGLang과 vLLM을 활용한 고속 추론 🏎️
Qwen3-Next의 뛰어난 추론 효율성을 극대화하려면 **SGLang**이나 **vLLM**과 같은 전용 추론 프레임워크를 사용하는 것이 좋아요. 특히 긴 문맥 추론에서 훨씬 더 나은 성능을 기대할 수 있습니다.
SGLang과 vLLM은 Qwen3-Next의 **다중 토큰 예측(Multi-Token Prediction, MTP)** 기능을 활용하여 추측 디코딩(Speculative Decoding) 효율을 극대화할 수 있도록 최적화되었어요.
마무리: 핵심 내용 요약 📝
정말 놀랍지 않나요? Qwen3-Next는 기존 모델들의 한계를 뛰어넘는 새로운 아키텍처를 제시하며, 학습과 추론 모두에서 혁신적인 효율성을 보여주었어요. Gated DeltaNet과 스탠다드 어텐션의 결합, 그리고 극도로 희소한 MoE 구조는 AI 모델의 미래를 다시 한번 생각하게 합니다. 앞으로 Qwen3-Next를 기반으로 더 발전된 **Qwen3.5** 모델이 등장할 거라고 하니, 정말 기대되지 않나요? 😊
Qwen3-Next 핵심 정리
자주 묻는 질문 ❓
'AI' 카테고리의 다른 글
| FTC의 칼날, AI 챗봇 '정신병' 논란의 전말과 미래 (1) | 2025.09.15 |
|---|---|
| "이거 PPT로 만들어줘" 클로드 AI 파일 생성 기능, 직장인 필수 스킬 될까? (1) | 2025.09.15 |
| [2부] 보스턴 다이내믹스도 선택한 Jetson Thor, 그 무한한 가능성 (9) | 2025.09.01 |
| [1부] 휴머노이드 로봇의 심장, NVIDIA Jetson Thor 스펙 총정리 (4) | 2025.09.01 |
| 충격! 스탠포드 최신 연구가 밝힌 AI의 신입사원 고용 영향 (6가지 팩트) (6) | 2025.08.29 |



